
![[Algorithm] ZUC —— “祖冲之”流密钥算法的代码解释](https://golden-forest.top/f47066e331aeeefd695c72ea24d732e1.jpg)
ZUC算法分析
本文写于作者进行密码学课程实验过程中,会以“初学者”的视角去解读。不涉及CTF中的逆向、密码知识,只为做深入理解并为后面复习所用。文章代码源于AI生成,作者专门调过提示词,按照GB/T33133.1—2016标准设计,可能与其他标准或实现顺序有区别,如有问题,请联系作者:(后面开个仓库)
前言
首先,想了解ZUC算法是什么:祖冲之算法,也称为ZUC算法,是一种由中国学者自主设计的同步序列密码算法(流密码),主要用于加密和数据完整性校验。它是中国第一个成为国际密码标准的算法,被采纳为4G移动通信系统(LTE)的国际标准...
以下是GB/T33133.1—2016标准中的算法结构图:
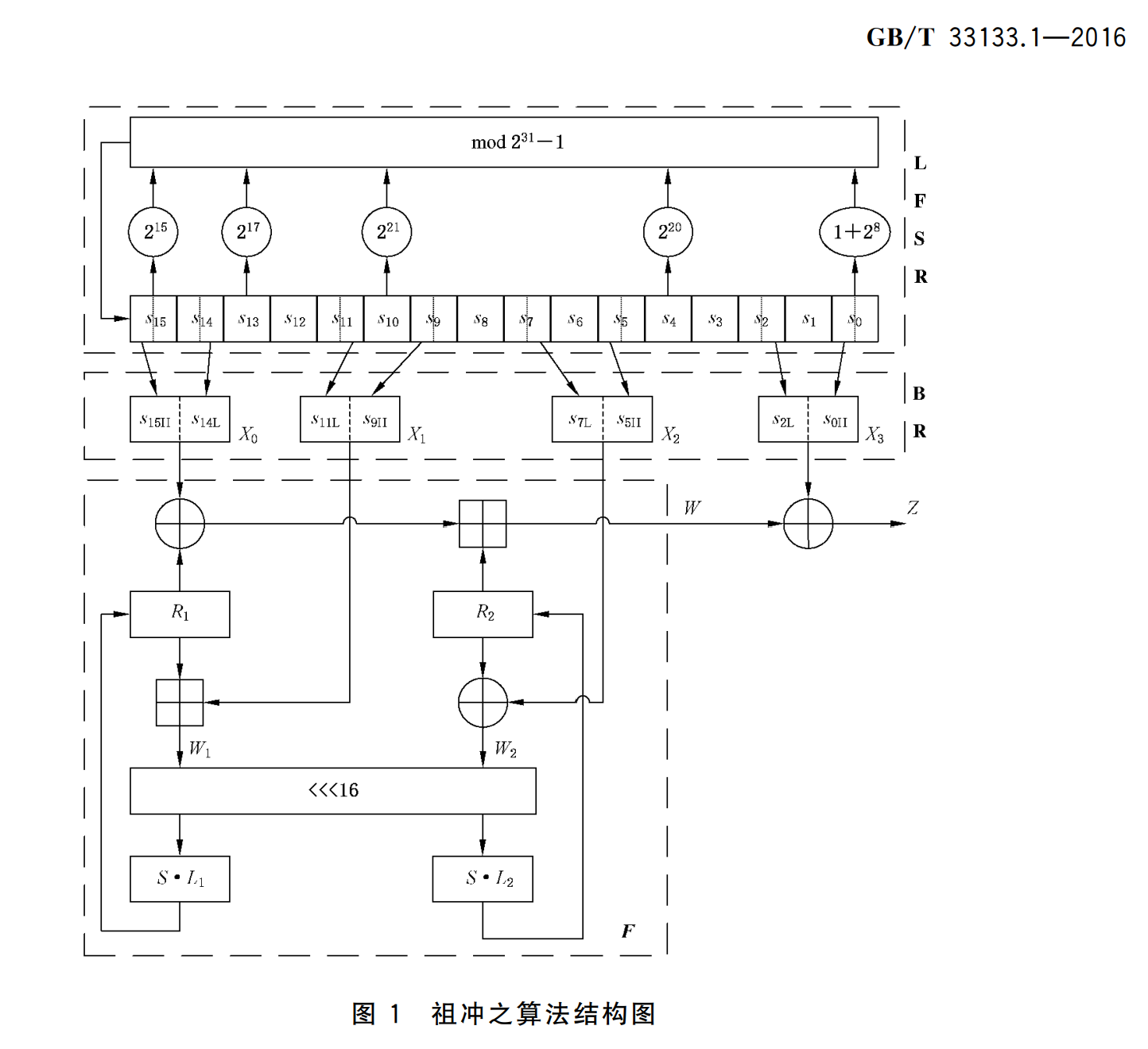
现在看不懂还很正常,下面我们会结合代码一层层地解释。简单来说,ZUC算法是一种可以用于生成 流密钥的算法,用于 流密码加密,其核心有三个步骤
- 比特重组(BR)
- 非线性函数F(F)
- 线性反馈移位寄存器(LFSR)
代码实现上,还需考虑预处理一下输入
- 预处理
而得到的 流密钥用于加密解密只需要简单异或一下就行了
- 加密解密
综上,本文将分为以上5部分去尽可能完整且详细地介绍ZUC算法
PS:本文将以递进式的方式去介绍,而不是分块式,建议跟着一步步看,不然容易出现思维跳跃
(以下是程序源码:)
1 | ############## ZUC密钥生成算法实现 ############## |
预处理
在开始介绍算法之前,先来我们传入的参数是什么意思:
1 | key = bytes([0x00] * 16) # 密钥 |
- 密钥:128位(也就是16字节)。核心参数,决定了加密系统的根本安全性。因为其从根本上决定了伪随机密钥流的“基座”或“种子模式”。不同的密钥会产生完全不同的、不相关的密钥流序列。需要严格保密
- IV(向量):128位(也就是16字节)。密码学中存在一种
重放攻击(作者不懂,不过多介绍),而引入向量可以确保密钥流的随机性与唯一性,防止重放攻击。通常不需要保密,因为每次加密都应该引入一个完全不同、唯一的向量
IV(向量)与密钥协同工作,为每次加密都会生成一个独一无二的起始点。即使用相同的密钥,只要IV(向量)不同,ZUC算法产生的密钥流就会完全不同。这确保了即使加密了两段完全相同的明文,得到的密文也会截然不同。
- 待加密的内容:可以是任意、随机、完全无限制的一段数据。ZUC是一种流密钥,意味着生成的一个个bit的
流密钥,我们只需要生成与待加密数据对应长度的密钥字即可进行加密。
了解了这些以后,我们来看我们代码的主函数,在python中也就是:
1 | # main() |
那么我们直接来看ZUC的加密函数:zuc_encrypt(key, iv, data)
1 | ()def zuc_encrypt(key, iv, data): |
可以看到,整个加密函数一共分为这几步:
- ①将我们提供的参数,也就是将key、IV传入一个初始化函数
- ②加载算法的起步阶段函数,但是我更喜欢称其为“预热”阶段
- ③计算所需的密钥字数量,生成密钥流,也就是启动ZUC算法的工作模式
- ④最后将密钥流转换为字节流(其实也就是需要和数据的格式一致),将数据与密钥流异或,完成加密
其中前三部是我们要关注的重点,也就是密钥流是如何来的,最后的异或其实无关紧要
我们来一步步看下去
传参
先来看我们的key和iv被用来干什么了:
1 | class ZUCAlgorithm: |
调用这个类会触发构造函数(__init__ 魔术方法),其主要干了这么几件事:
- 将key、iv传给类成员 :
self.key = key、self.iv = iv - 将R1、R2置零(先不管,后面介绍)
- 声明LFSR的16个31位寄存器,以数组实现(先不管,后面介绍)
- 调用了
_init_d_constants()、ZUCSBox()初始化(照样先不管,马上就知道用来干什么)
都是些初始化,由于其中参数我们很多都不认识,所以先不管
这里展示的主要原因是留个印象,接下来我们会一一介绍
接下来我们返回上一层,来看预热函数:initialization_phase()
1 | def initialization_phase(self): |
接着我们来看预处理阶段最重要的密钥装入部分,在算法标准结构图中,也就是将原本空的s0-s15装入内容:

密钥装入
先贴代码
1 | def key_load(self): |
这里指的密钥装入,事实上指的是将key + iv 配合用于初始化 LFSR的16个寄存器,即s0-s15
简单介绍以下 LFSR是什么:全程“线性反馈移位寄存器”,一个会进行移位的寄存器,其输入由自身获得,可以产生“伪随机(最大周期是 2^n - 1)”的输出序列,密码学中它的作用是快速产生一个长周期的伪随机密钥流
具体 LFSR我们下面会介绍,这里要讲的是这段代码是如何将我们的key + iv装入这16个寄存器的:
- 进行16轮操作,每轮操作如下:
- ①遍历,从key和iv提取一个字节,分别记作k_i、iv_i
- ②第i个寄存器记作s_i
- ③将s_i 赋值为 :k_i的后8位 + d_i的后15位(先别急马上介绍)+ iv_i的8位
- ④这样子每个s_i就是31位了
可以看到,我们传入的key并不是完全利用到了,而是只取其8位,配合一个15位的参数d_i以及iv中的8位,拼接成一个 8 + 15 + 8共31位的值
这里我们可以看到出现了一个奇怪的参数 :d_i
它在前面被我们忽视了:_init_d_constants()
1 | def _init_d_constants(self): |
d_i可以看到,它其实是一段段二进制参数,其作用是:通过将密钥(ki)、常数(di)和初始向量(ivi)连接起来,保证了即使密钥或初始向量部分相同,LFSR的初始状态也会因常数的引入而不同。这防止了初始状态全为零或其他弱状态,从而避免了密码分析中的弱点。
在ZUC算法中,di 是一组预定义的15位常数(即每个 di 占15位),用于LFSR的初始化。这些常数是ZUC标准的一部分,由算法设计者精心选择,以优化LFSR的统计特性。我们只需要记住:di是配合我们提供的key和iv使用、用于装填空的LFSR寄存器用的
我们还注意到,每个寄存器只取31位,其原因,作者这里也不完全理解(数学不好),贴上查到的解释:
- ZUC的LFSR不是工作在传统的基于异或的GF(2)上,而是工作在模素数 p = 2³¹ - 1 的有限域 GF(p) 上
- 这个素数 p 是一个 梅森素数 。在GF(p)上设计的LFSR,如果其反馈多项式是一个本原多项式,那么它能够达到的 最大周期是 p - 1 = 2³¹ - 2 。这是一个巨大的、已知的、且是可能达到的最大周期。
- 如果使用32位(2³²),那么模数将是2³²。在GF(2)上,基于异或的LFSR的最大周期是2³² - 1,这虽然也很大,但ZUC的设计者选择了GF(p)这条路径。
而key、iv各取8位的原因是将Key、IV和常数d高度混合混,使得分析密钥和输出序列之间的关系变得极其困难
总之,进行16轮这样的key、d、iv的混合后,我们就得到了16个已经“装满货物”的寄存器,到这里,我们提供的key与iv也就尽完它们的职责了,也就是完成密钥装入
initialization_phase()函数接下来还有一步:设置R1、R2为0,还是先跳过(或者直接去看 非线性函数F部分也可)
然后是开始进入到一个32次的循环,这也是ZUC算法的重点,但是我们先一步步介绍循环的函数到底是什么,再来说明为什么循环32次
线性反馈移位寄存器(LFSR)
虽然给的代码是 比特重组(BR)——> 非线性函数(F) ——> 线性反馈移位寄存器(LFSR),但是由于这个部分与后面两个部分有紧密关联,所以先提前给出
还记得我们前面说过:LFSR密码学中它的作用是快速产生一个长周期的伪随机密钥流,其生成的密钥流就是为后面进行混淆的对象,也就是说,你可以把 LFSR当作我们生成的ZUC密钥流的“种子算法”,负责维护算法的大部分内部状态。
伪随机的原因是其具有周期性,最大为 2^n - 1(原理可自己查查),但是我们设置16个31为LFSR意味着状态空间高达496位,在数学上足以抵抗暴力破解
那么它是如何长周期产生一个长周期的伪伪随机密钥流的呢?
我们结合一下算法标准结构图来看看其实际计算流程:
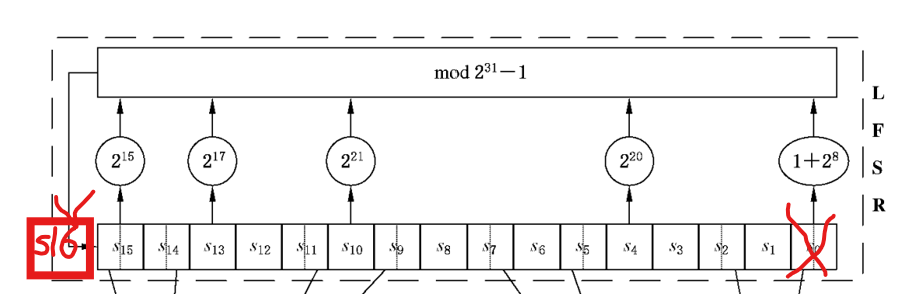
(简单处理了一下)
其逻辑就是:取s15、s13、s10、s4、s0这5个值,进行一堆运算之后,得到一个新值s16,并将s0踢出去,将得到的s16放到最后。
这个流程就像是我们砍竹子(比喻也许不够恰当),一根竹子一共16节(最多且必须),我们把最头部的一节砍了(丢掉s0),然后底部长出一根新节(生成s16)。这样子就能保证,整根竹子都处于最嫩的状态(一直在更新),且会一直保持生长(一直保持16节)
那么我们是如何得到这个新的竹节,也就是 s16的呢?
来看代码:lfsr_initialization_mode(u)
1 | def lfsr_initialization_mode(self, u): |
但是,如果你先提前全部浏览整个文章,会发现还有个函数与LFSR有关:lfsr_work_mode(self)
1 | def lfsr_work_mode(self): |
s s16有两种生成办法?!这实际上这告诉我们:LFSR有两个状态。为什么?
这实际上就是ZUC算法的核心设计:这两种模式的存在是为了解决一个根本矛盾:如何从一个确定的密钥和IV出发,最终生成一个随机、不可预测且“高效生成”的密钥流?答案就是加入“混淆与扩散”。
- 密钥装填:实现了从一个密钥(key)和向量(IV)出发
- 初始模式 :目的是 “混淆和扩散” ,将算法内部状态“打乱”,使其达到一个充分随机的起始点,看不出内部状态与我们的IV、密钥的关系(注意只是起始点,还是不能直接作为密码使用!后面会解释)
- 工作模式 :目的是 “高效生成” ,可以快速得到安全可靠的密钥流。
我们来一步步介绍这两个函数(状态)
初始模式
首先来看 lfsr_initialization_mode(u),也就是 LFSR初始模式:
我们在前面已经进行过 密钥装入,也就是把IV和key还有常数d装进16个31位空的寄存器里面了,接下来为了实现我们“看不出内部状态与我们的IV、密钥的关系”的目标,就需要打乱现在16个31位寄存器的关系
可以看到,初始模式生成 s16的过程需要提供一个31位的输入 u,其来源可以在 initialization_phase(self)函数中看到,来自 非线性函数F的运行结果,我们后面再讲这一步,这里我们就把 u当作一个安全的、可靠的“搅屎棍”
先来看我们计算s16的代码
1 | # (1) 计算v |
可以看到LFSR的初始模式,计算中间值 v与 S16时,分别调用了两个函数: mod_231_1_mult(self, a, b)、mod_231_1_add(self, a, b)
1 | def mod_231_1_add(self, a, b): |
这两个函数其实就是我们结构图中对 s15它们进行的运算,本质是是一种 模运算(记住如何实现就行)
来介绍一下 v:LFSR线性特性的集中体现:
- 线性混合 :
v是由LFSR中 5个特定寄存器s15, s13, s10, s4, s0通过线性组合计算得出的。 - 扩散作用 :这些寄存器在
LFSR中分布较广(索引0,4,10,13,15),确保了LFSR状态的广泛参与。 - 数学基础 :计算基于
Galois域 GF(2^31-1)上的运算(与31位寄存器对应),保证了LFSR能达到最大周期。
没事,我也看不懂这里面的数学逻辑,但是,简单说:v 代表了LFSR"本来应该"按照线性规则生成的下一个状态。
初始模式最关键的是 s16的得到方式,将前面得到的 线性的v与我们给的 非线性的u进行了 模加法,然后丢掉 LFSR最前面的一个值 s0,将 s16放到最后,这意味着,相当于在 LFSR的线性序列中植入了非线性基因
举个例子:
对于一个一般的可破解 LFSR序列在程序的眼里长这样: a-b-c-d-e-f-1-2-3-4-5-6
在加入了 s16整个非线性基因后,可以长这样 b-c-d-e-f-1-2-3-4-5-6-🔣
而这个🔣即使与前一个状态:a-b-c-d-e-f-1-2-3-4-5-6有密切关系,但是就算你是计算机本体都看不出这玩意到底和我们的密钥、IV有半毛钱关系,实现了我们“扩散与混淆”的目的
当然简单一轮是完全不够的, initialization_phase(self)函数中进行了32轮这样的****非线性基因植入,足够达到了一个高度随机化的"混沌"状态.
工作模式
达到我们要的混沌状态之后,就不需要我们继续提供 非线性的u了,之后只需要让它愉快地产生随机密钥流即可,在代码中,我们可以看到 这个模式下的 s16算法与初始模式的 v一致,即:在我们初始模式中,生成 v的算法,就是工作模式生成 s16的算法,就不过多介绍了
为什么不能直接作为密钥使用
但是!正如我们代码中看到的,虽然 key、IV和 LFSR生成的密钥流序列的 内部关系是非线性的,但是 LFSR生成的密钥流的 外部关系是线性的,这意味着攻击者只需要截获一小段输出序列(2n个比特),就可以通过解一个线性方程组(例如使用 Berlekamp-Massey算法)轻松地推算出 LFSR的反馈多项式和整个后续输出序列,从而完全破解加密。
所以,不能直接将得到的 LFSR密钥流作为真正的密钥流使用,那该怎么办呢?接下来我们要介绍的 比特重组和 非线性函数F就是为了解决这个问题而设计的
比特重组(BR)
这一步代码非常简单,来看 比特重组的函数:bit_reconstruction()
1 | def bit_reconstruction(self): |
比特重组(BR) 是ZUC算法中一个非常精巧且关键的设计,它充当了 LFSR(线性部分)和 非线性函数F(非线性部分)之间的"桥梁"。简单来说,比特重组做了一件看似简单但至关重要的事情:它从 LFSR的16个寄存器中,有选择地、按特定规则抽取一些位,然后重新打包成4个32位的字(X0, X1, X2, X3),供后续步骤(非线性函数F)使用
具体来说,其抽取的寄存器、每个寄存器抽取的位是固定的:
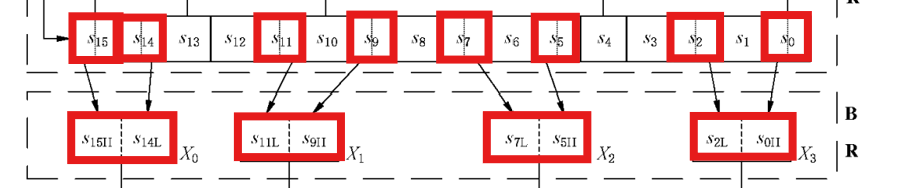
由于 LFSR的更新是“去头填尾”,相邻寄存器存在强关联,而 比特重组以不连续、广泛的方式去抽值,可以去除这种强关联,达到扩散的目的
而 比特重组返回的结果,4个32位字 X0, X1, X2, X3中,只有 X0, X1, X2 被送入 非线性函数F 当中,而 X3将会与 非线性函数F得到的 w进行异或,得到我们用来进行 LFSR的初始模式的 u,这样设计即实现了非线性,又保证了效率
知道了 比特重组的作用后,就可以看整个ZUC算法最复杂的一部分——非线性函数F了
非线性函数F
非线性函数F 是ZUC算法的安全核心,它负责将LFSR产生的 线性密钥流 转换为 非线性密钥流。让我们先看看它的代码:
1 | def nonlinear_function_F(self, X0, X1, X2): |
可以看到,其所用参数就是我们 比特重组一步得到的 X0、X1、X2
而返回的输出 W,实际上在该函数开头通过 W = (X0 ⊕ R1) + R2 mod 2^32这段代码就已经计算完毕了,那么后面一大段函数用来干什么呢?
而其中所需用到 R1、R2两个前面提到过的参数与 sbox_32(self, X)、linear_transform_L1(self, X)、linear_transform_L2(self, X)这三个函数又是什么呢?
记忆单元R1、R2
我们先来介绍 R1、R2这两个参数到底是什么:在ZUC算法的文档中,R1和R2被称为 32位记忆单元 。它们本质上就是两个32位的寄存器,在算法运行过程中会不断地被更新。同时保持非线性关系
正如其名字一样,它们两的作用是“记忆”,说起来有点抽象,我们先来思考这么一个问题:
- 如果每一轮产生的密钥流都只依赖于当前
LFSR的状态,那么密钥流之间的关系就是相互独立的。攻击者可以孤立地分析每一段密钥流(这里一段密钥流实际上就是一次LFSR运算生成的新31位数据)。 - 这意味着,攻击者截取到的密钥流片段对攻击来说是有意义的(具体多少没细研究)
- 如何在不断生成的一段段密钥流中,建立起联系,使得攻击者即使拿到其中一个片段都没有用呢?
设计者的解决方案是:引入 R1、R2这两个“记忆单元”,“记住”当前的 密钥流状态,让它们两加入到生成新的密钥流过程中。意思是:在 LFSR的第 n轮的计算中,此时 R1、R2它们的状态是第 n-1轮计算的结果,并且,由于迭代,当前的 R1、R2包括了过去所有轮次的“历史信息”,更准确地说,此时 LFSR的第 n轮的计算,与前 n-1轮都有关系
这使得 密钥流不再是一个独立的序列,而是一个连续的、前后高度关联的数据流。第100个 密钥字依赖于第99个,第99个依赖于第98个……一直回溯到初始化阶段。这极大地增加了密码分析的难度。
回到我们开头的看到的ZUC算法初始化函数,由于我们一开始并没有进行过 LFSR运算,所以开始一要将 R1、R2置0
然后回到 非线性函数F,我们已经知道了 R1、R2的作用了,所以我们也能理解 w的结构图中的生成是如何而来的了:
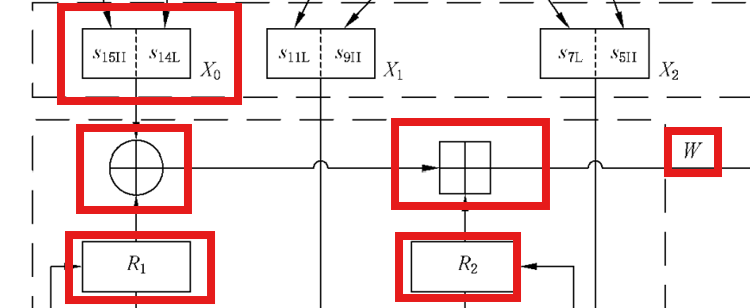
即↓
1 | # (1) W = (X0 ⊕ R1) + R2 mod 2^32 |
这里就体现了后面生成的密钥流是与前面生成的密钥流有强联系的。
知道了 R1、R2的作用后,我们来来看看更新的 R1、R2的算法到底是什么:
为了方便理解接下来个个函数的关系与顺序,先奉上结构图(稍微处理了一下)
1 | ... |
Sbox
按照图中标号顺序,我按照倒序的方法来介绍
R1、R2的更新过程。
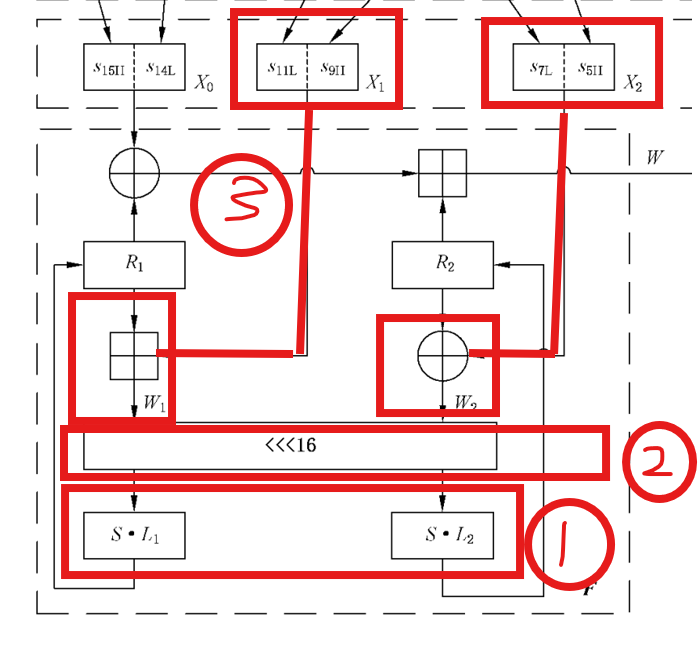
首先我们来看整个代码最核心的部分——非线性的Sbox。我们在前面提到一个类 ZUCSBox(),其构造函数长这样:
1 | def __init__(self): |
S0和 S1是两个精心设计的“输入8位,输出8位”的非线性查找表,简称 Sbox,但是,我们在上面代码可以看见,这个 Sbox一共有256个8位(两个16进制)值,如何实现的**“输入8位,输出8位”**呢?
其实,在 sbox.sbox_32(self, X)函数中就已经展示了查找的方法:
1 | def sbox_32(self, X): |
这个函数接受了一个 32位x,然后,将其分为4个8位的值,即一个2位16进制数(形如0xFF),将其作为索引直接取 Sbox中的对应的值(也是8位),最后将得到的4个对应得8位值拼接为一个32位值
这里不难看出,8位的值作为索引共有2^8=256种情况,所以是256个8位值
而有两个 Sbox的原因,主要有三:
- 如果只用一个
Sbox,算法中会出现很多的对称性和重复模式。交替使用S0和S1打破了这种对称性,增加了算法的复杂性。 - 两个不同的
Sbox意味着攻击者需要同时分析两个独立的非线性系统,而不是一个。这样可以平方级地增加了代数攻击的难度。 - 不同的
Sbox减少了出现固定点(如S(x) = x)和其他简单代数关系的概率。
顺带一提,为什么是8位?解释有很多,不过最好的记忆方法是:
- 8位(其实就算1字节)是现代计算机体系结构的基本处理单元。
由于本身 Sbox是 非线性的,于是有了以下 非线性传递链(以下参数都是前面出现过的):Sbox -> R1/R2 -> w -> u -> LFSR生成的密钥流 -> ZUC生成的密钥流
总而言之,新 R1、R2的值就是通过传入 32位x作为索引,在 Sbox中查找对应的值得到的,那么,这个 32位x又是怎么来的呢?
线性变换
还是刚刚那个函数:
1 | ... |
可以看到我们传入的 32位x的参数实际上是另两个函数的计算结果:linear_transform_L1(self, X)、linear_transform_L2(self, X):
1 | def linear_transform_L1(self, X): |
这两个函数称之为 线性变换,其最重要的功能即是实现“扩散”,简单来说,经过这么一个 线性变换操作,在 密钥流中,只要我们改动小小一个bit,就会影响输出中多个、看似不相关的bit,这极大确保了 整体密钥流的安全性
那么为什么会有两个 线性变换算法呢?粗俗点讲,这两个 线性变换的扩散程度不一样,使得攻击会更复杂,且攻击者还需猜测用的那种变换,增强安全性
虽然两个函数看起来代码很长,但是数学公式很好理解:L1(X) = X ⊕ (X <<< 2) ⊕ (X <<< 10) ⊕ (X <<< 18) ⊕ (X <<< 24)、L2(X) = X ⊕ (X <<< 8) ⊕ (X <<< 14) ⊕ (X <<< 22) ⊕ (X <<< 30)
对我们来说用代码实现还是很好理解的
交叉重组
最后,我们来看看是谁被进行了 线性变换,也就是 R1_input,来看看它是如何得到的
1 | # W1 = R1 + X1 mod 2^32 |
可以看到,在我们进行 线性变换之前,还将 R1、R2处理了一下,这一步叫做 交叉重组,其思路也简单,就是将 R1、R2,配合我们 比特重组得到的 X1、X2进行重新排列组合,这样做的目的也是我们一直在做的:加入“扩散”。将 R1、R2混合在一起,这样这两个参数的内在关系也不再是孤立的了,这样攻击者光有其中一个参数也不足以造成一次有效攻击
其数学逻辑看代码就很好理解了,就不做过多介绍到目前为止,我们就介绍完了 非线性函数F的所有关键操作了,但是由于我们是倒着讲的,所有这里我们重新梳理以下真正的操作:生成新w -> 将R1、R2交叉重组 -> 线性变换 -> Sbox查表
经历了这么复杂的一个过程,我们就能将我们从 LFSR中生成的密钥流进行“扩散与混淆”,保证了密码的安全性,这一个个经过“扩散与混淆的”密钥流,才能够真正作为我们去可靠使用的密钥去加密数据
小梳理
到这里,我们终于看完了初始化函数:zuc.initialization_phase(),回顾一下我们干了什么:
- 首先,我们看到开始会初始化一堆我们后面将会用到的参数,包括
R1、R2、Sbox填充等 - 其次,我们理解了我们传入的参数
key、IV的作用 —— 用于填充空的16个31位寄存器(LFSR) - 之后,我们进行了32轮如下操作,其中真正的目的是完成
LFSR的初始模式,就是要将key、IV完全混合在我们的LFSR中,即进行LFSR内部关系的“扩散与混淆” - 第一步,我们看到,进行了
比特重组,也就是取LFSR中的几个值去做混合,为接下来的非线性函数F做预处理工作 - 第二步,我们把处理过的参数
V0....V3交给了非线性函数F,其进行了生成新w -> 将R1、R2交叉重组 -> 线性变换 -> Sbox查表等操作后,得到了下一次要用的R1、R2,以及处理好的w,对32位的w去除1位,就得到了我们要加入LFSR的u - 第三步,我们将生成的
u给加入到新的LFSR中。如此进行32轮,就再也看不出当前LFSR的密钥流与我们初始key、IV的关系了
加密解密
接着我们来看接下来的关键函数:keystream=zuc.generate_keystream(key_words_needed)
1 | def generate_keystream(self, L): |
这里有一个疑问点:为什么还要进行一次工作阶段初始化?
其实很简单:我们前面进行 比特重组+非线性函数F生成的值,最后都加入到 LFSR中了,也就是说,这些 密钥流字都是“非线性改造过的”,但是,在工作模式下的 LFSR,我们要的是“纯线性”的 密钥流字,所以,我们需要进行一次工作初始化,即把第一次生成的 密钥流字给“丢弃了”
当然另一种方便记忆的解释是:好比汽车发动,你得先开启引擎让他开一会看看正不正常运行
之后,我们就可以确保接下俩的 LFSR生成的密钥流之间是线性的,但是!是线性的,也就意味着密钥流之间是孤立的、密钥流也是不安全的,总而言之,其生成的密钥流不能直接作为密码
所以,我们还要对 LFSR生成的密钥流进行 比特重组+线性变换,也就是在进行一次“扩散与混淆”。这一步就是去除了 密钥流之间的外部线性关系
现在,只要我们按照给出待加密数据的长度,生成相应长度的密钥流,然后进行简单的操作:encrypted.append(data[i] ^ keystream_bytes[i]),就完成了加密操作了
上面这步可以看出,密文 = 密钥 ^ 明文,也就是说,ZUC密码是对称密码,所以,解密方式就算把密文当作明文丢进去,按照原来的 key、IV再次运行一次加密即可

在这里留下你的足迹...